
1. 개요
SyntaxHighlighter는 블로그나 웹사이트에서 사용할 수 있는 코드 구문 하이라이터입니다.
HTML, Javascript, Python, C 등 여러 언어에 사용할 수 있고 스크린샷 같은 방식보다 가독성이 좋습니다.
2. 파일 다운로드
최신 버전은 4.0인데 별도의 빌드 과정이 필요합니다. 빌드를 해서라도 4.0 버전을 사용하려는 분들은 GitHub에서 직접 다운로드 하십시오.
https://github.com/syntaxhighlighter/syntaxhighlighter
GitHub - syntaxhighlighter/syntaxhighlighter: SyntaxHighlighter is a fully functional self-contained code syntax highlighter dev
SyntaxHighlighter is a fully functional self-contained code syntax highlighter developed in JavaScript. - GitHub - syntaxhighlighter/syntaxhighlighter: SyntaxHighlighter is a fully functional self-...
github.com
저는 빌드하기 귀찮으니... 3.08 버전을 사용합니다.
혹은 다음 링크를 이용하세요
https://github.com/syntaxhighlighter/syntaxhighlighter/archive/3.0.83.zip
상기 소스를 다운 받고 압축을 풉니다
3. Scripts와 Styles내 파일들 업로드하기
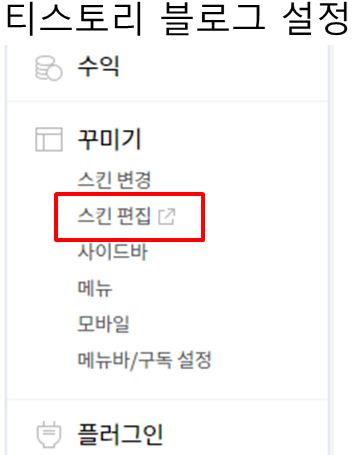
필요한 파일들을 업로드 하기 위해 업로드 페이지로 들어갑니다
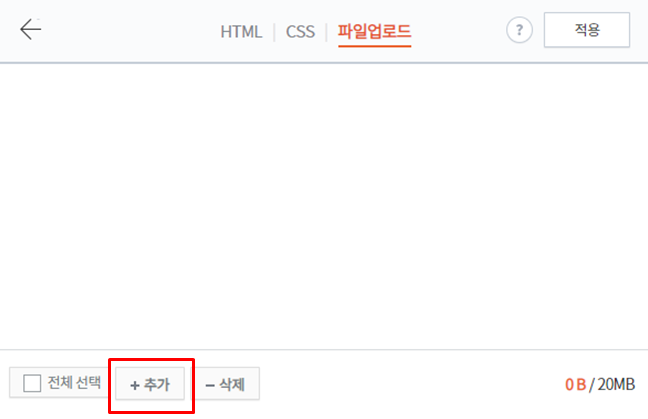
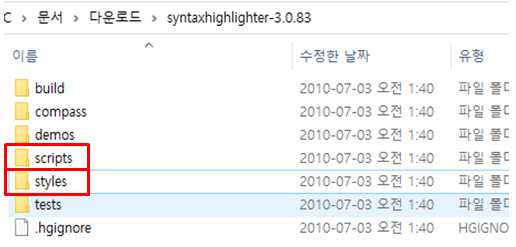
압축을 푼 폴더에서 scripts 폴더와 styles 폴더에 있는 파일들을 전부 업로드합니다.
4. HTML 편집하기
HTML 페이지로 들어가 아래와 같이 필요한 파일들을 채워 넣습니다.
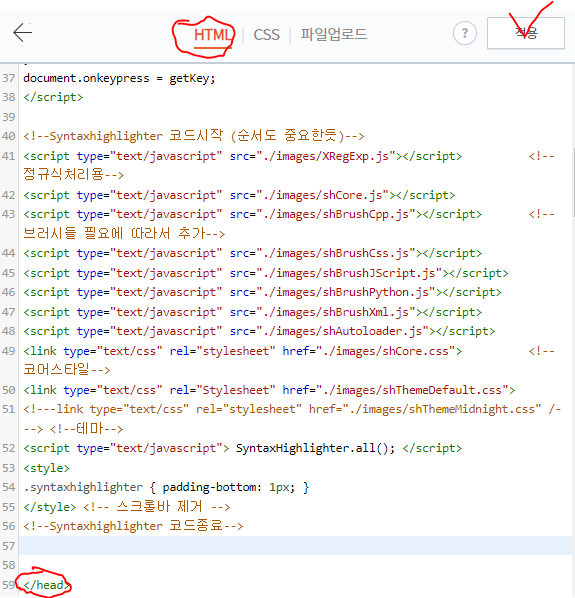
<!--Syntaxhighlighter 코드시작 (순서도 중요한듯)-->
<script type="text/javascript" src="./images/XRegExp.js"></script> <!--정규식처리용-->
<script type="text/javascript" src="./images/shCore.js"></script>
<script type="text/javascript" src="./images/shBrushCpp.js"></script> <!--브러시들 필요에 따라서 추가-->
<script type="text/javascript" src="./images/shBrushCss.js"></script>
<script type="text/javascript" src="./images/shBrushJScript.js"></script>
<script type="text/javascript" src="./images/shBrushPython.js"></script>
<script type="text/javascript" src="./images/shBrushXml.js"></script>
<script type="text/javascript" src="./images/shAutoloader.js"></script>
<link type="text/css" rel="stylesheet" href="./images/shCore.css"> <!--코어스타일-->
<link type="text/css" rel="Stylesheet" href="./images/shThemeDefault.css">
<!---link type="text/css" rel="stylesheet" href="./images/shThemeMidnight.css" /---> <!--테마-->
<script type="text/javascript"> SyntaxHighlighter.all(); </script>
<style>
.syntaxhighlighter { padding-bottom: 1px; }
</style> <!-- 스크롤바 제거 -->
<!--Syntaxhighlighter 코드종료-->입력을 다 했으면 "적용" 버튼을 누릅니다.

4. 사용 방법
블로그 글쓰기에서 HTML모드로 진입합니다.
아래와 같은 방법으로 직접 입력합니다
<pre class="brush:사용할 언어>
소스 코드
이것
저것
</pre>
예를 들면...

'나는 컴쟁이다~!' 카테고리의 다른 글
| CSR V4.0 Bluetooth USB dongle Driver (0) | 2023.07.21 |
|---|---|
| 티스토리에서 MathJax을 이용해서 수식 입력 (0) | 2022.02.05 |
| 제 2의나라 쿠폰 "회원 번호" 자동으로 입력되는 바로 가기 만들기 (0) | 2021.11.24 |
| [윈10] VPN 자동 재접속 (자동 트리거) 기능 적용하기 (0) | 2020.06.06 |
| 구글맵의 타임라인에 접속하면 error 400 bad request가 표시될때 조치 방법 (0) | 2018.03.02 |